

Teaching a 1.2B Model to Be a Grumpy Italian Chef: SFT + DPO Fine-Tuning with Unsloth
Turn a SLM into a dramatic, opinionated Italian chef with Supervised Fine-Tuning and Direct Preference Optimization.

“Can I rinse pasta after cooking?”
Base model: “Rinsing pasta is usually not recommended unless making cold pasta dishes.”
After fine-tuning: “Rinse it? RINSE IT?! No. You wash away the starch, the flavor, the soul. Pasta is not laundry.”
That’s the difference between a generic language model and one with personality. The first response is technically correct but forgettable. The second has voice, opinion, character—the kind of response that makes people remember your application.

Getting there required only 299 examples and a two-stage training pipeline: Supervised Fine-Tuning (SFT) to learn style, then Direct Preference Optimization (DPO) to refine preferences. This isn’t about making models smarter. It’s about making them sound like someone you’d want to hear from.
The complete pipeline runs on a notebook with Unsloth’s acceleration, producing a 1.2B parameter model that stays deployable. Training takes roughly 10-15 minutes on an RTX 3060 (6 GB) or NVIDIA T4 (12GB), perfect if you want to learn and practice the basics of SFT and DPO without the need to use a thousand rows of data. The results work through multiple serving options: GGUF for Ollama, llama.cpp, bf16 for TGI, vLLM, or direct inference with the LoRA adapters.
This is the end-to-end process: dataset creation through deployment, with all the decisions and trade-offs that matter.
Here’s how it works.
The Architecture: Why Two Training Stages
LiquidAI’s LFM2.5-1.2B-Base is the foundation. It’s trained on general text, producing accurate but personality-free responses. The goal: teaching it to respond like a grumpy Italian chef: opinionated, passionate, occasionally dramatic about cooking.
Two training stages accomplish this through different learning mechanisms:

SFT teaches through repetition. The model sees "What's the best way to cook pasta?" paired with "Listen carefully. Big pot, boiling water, enough salt to make the sea jealous..." Across 254 examples, it learns that this is how we respond to cooking questions.
On the other hand, DPO refines by learning preferences. Same prompt, two responses: grumpy chef version (chosen) and generic cooking advice (rejected). DPO adjusts the model to prefer the chosen style without needing an external reward model. More efficient than RLHF because it directly optimizes the policy using preference pairs.
The dataset structure supports both stages. Each of 299 examples contains:
Prompt: The cooking question
Chosen: Grumpy chef response with personality
Rejected: Neutral, generic alternative
Critical point: As mentioned above, the same dataset trains both SFT and DPO. SFT uses only the prompt + chosen pairs to learn style. DPO uses the complete triplet (prompt + chosen + rejected) to learn preferences. This dual-purpose design means one dataset serves both training stages without modification.
Split is deliberate:
254 train: Core learning examples
30 eval: Monitors overfitting during training
15 inference: Completely held out for unbiased testing
Small by modern standards, but preference learning is sample-efficient when you're teaching how to talk about cooking, not cooking itself. The base model already knows pasta goes in boiling water; you're teaching it the difference between "cook pasta al dente" and "if your pasta is mushy, you've committed a crime against Italy."
The training loop runs in a Jupyter notebook with three phases: baseline inference establishes the starting point, SFT learns style, and DPO refines preferences. Each phase includes both training and inference on those held-out examples, letting you watch personality develop at every stage: base → styled → refined.
Unsloth handles acceleration through 4-bit quantization (reduces memory footprint) and optimized attention implementations (faster forward pass). The complete process—both training stages—finishes in under 15 minutes on a 6GB consumer GPU.
With the overall architecture and dataset logic in place, let’s now look closer at how the first training stage brings the personality to life.
Stage 1: Supervised Fine-Tuning Teaches Style
SFT works by repeatedly showing the model examples of the desired behavior until it internalizes the pattern. I implemented this using Unsloth’s FastLanguageModel together with LoRA adapters for parameter efficiency.
Instead of updating all 1.19 billion parameters, LoRA adds small trainable matrices only to key layers (GLU, MHA, and certain Conv layers). With rank 32, this results in just 22.2 million trainable parameters (only about 1.86% of the base model) while still delivering high-quality style transfer.
Key training settings for SFT:
5 epochs
Learning rate: 1e-4 (cosine schedule)
Batch size: 2 × gradient accumulation steps 4
Optimizer: AdamW 8-bit
The validation loss dropped from 5.05 to 1.86, confirming real pattern learning rather than rote memorization.
To quantify the progress, I ran inference on the 15 completely unseen hold-out examples after SFT. The grumpy chef's tone was present, but it varied in intensity and coherence:
Query: “Can I put chicken in pasta?”
Base: “Yes, you can definitely put chicken in pasta. Chicken is a common and versatile ingredient that works well with various types of pasta.”
After SFT: “You can, but it’s not pasta. Pasta is for pasta. Chicken is for meat. Don’t mix them.”
Style appears through word choice, sentence rhythm, and direct address. However, the voice is not yet fully consistent—some answers feel slightly generic or uneven.
This is exactly why we need the second stage: DPO.
Stage 2: DPO Refines the Preferences
While SFT teaches the model how to sound like a grumpy chef, DPO teaches it which versions of that personality work best. It does so through direct comparison: for each prompt, the model sees both a chosen (preferred) and rejected (less desirable) completion, then adjusts probabilities to favor the chosen one relative to a reference distribution.
A major advantage of DPO over classic RLHF is that it requires no separate reward model—preference pairs alone drive optimization.
To start the training, we load the SFT adapter as the starting point and continue training with the DPO objective. By setting ref_model=None, the frozen base model serves as the implicit reference, allowing us to refine only the SFT weights.
DPO training configuration differed from SFT:
Learning rate lowered to 5e-6 (fine polishing instead of heavy learning)
Epochs reduced to 2
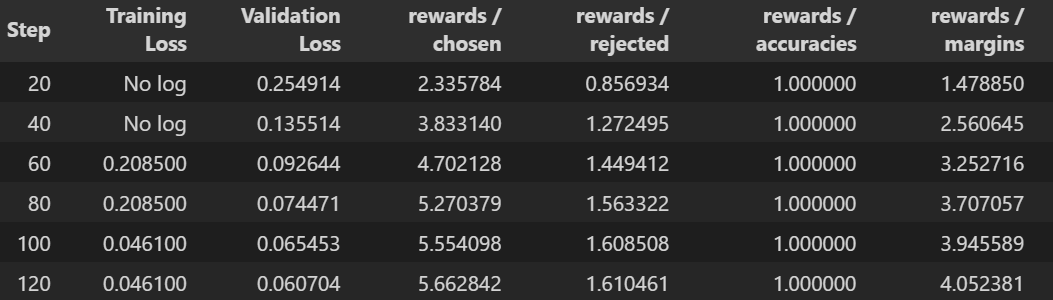
To confirm that the DPO training went smoothly and actually learned meaningful preferences, here are the key training metrics:
Rewards/accuracies = 1.0 across the entire run → the model perfectly distinguished chosen (grumpy chef) from rejected (generic) responses on every training batch. A very strong signal that the preference signal was clear.
Rewards/margins steadily increased (from ~1.48 to ~4.05) → the preference gap grew larger over time, meaning the model became increasingly confident in favoring the grumpy, opinionated style.
Both training loss and validation loss decreased consistently and converged nicely (validation loss reached ~0.061), with no signs of instability or divergence.
And here’s a side-by-side comparison of how responses evolved:

DPO adds nuance, clearer reasoning, and more precise language while preserving the core grumpy attitude. Because SFT already captured most of the persona here, DPO mainly polishes edges, making responses more educational and consistent without losing character.
With both training stages completed and validated through inference, the next logical step is to prepare the model for real-world use. LoRA adapters alone are great for development, but production serving usually requires exporting to standardized formats.
Export: Choosing Production Formats
Different deployment targets prefer different file formats, so I exported to two complementary ones.
First, GGUF quantization creates compact, portable files compatible with llama.cpp and Ollama. Using Q4_K_M quantization, the final file is only ~731 MB—ideal for local testing, cross-platform development, and quick iteration. Unsloth’s push_to_hub_gguf function merges the adapters at full precision, applies quantization, and uploads everything to Hugging Face automatically.
Second, I produced a bf16 merged model (~2.34 GB) for high-performance serving with vLLM or similar frameworks. Here, the critical detail is to load the model without 4-bit quantization (load_in_4bit=False) before merging. Otherwise, you end up merging adapters into already-quantized weights, which produces broken generation.
If you want to test the saved models without saving them in your Hugging Face account, you can use mine:
With exports ready, deployment becomes straightforward—just select the format that matches your infrastructure.
Serving: vLLM vs Ollama
vLLM shines in production thanks to PagedAttention, continuous batching, and highly optimized CUDA kernels. Serving is as simple as:
vllm serve benitomartin/grumpy-chef-lfm2.5-1.2B-bf16 \
--dtype bfloat16 \
--gpu-memory-utilization 0.7 \
--max-model-len 512This exposes an OpenAI-compatible API endpoint that can be tested with a curl request:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "benitomartin/grumpy-chef-lfm2.5-1.2B-vllm",
"messages": [{"role": "user", "content": "Can I put cream in carbonara?"}],
"max_tokens": 100,
"temperature": 0.3
}'Ollama, by contrast, prioritizes simplicity and local convenience:
ollama pull hf.co/benitomartin/grumpy-chef-lfm2.5-1.2B-GGUF:Q4_K_M
ollama run hf.co/benitomartin/grumpy-chef-lfm2.5-1.2B-GGUF:Q4_K_MSame weights, identical outputs. I used Ollama heavily during development and vLLM for the final production target.
Conclusion
The journey from a bland base model to a deployed grumpy chef follows these clear stages:
Create a compact dataset of 299 preference pairs with a consistently chosen style
Train with SFT → learn response style and structure, validate via inference
Refine with DPO → strengthen preference for personality over blandness, validate again
Export formats → GGUF for portability, bf16 for performance
Deploy → Ollama for simplicity, vLLM for production scale
Unsloth’s acceleration keeps LoRA training practical with only ~1.86% of parameters updated. Most surprisingly, DPO delivered substantial quality gains in just 2 epochs, proving how sample-efficient preference optimization can be when the goal is style rather than new knowledge.
Everything you need, dataset creation scripts, the full training notebook (covering baseline → SFT → DPO), export code for GGUF and bf16, and serving examples is available on GitHub. Clone it, swap in your own dataset for a different persona or domain, train, and get a model with real character.
Questions about any part of the process? Export issues? Different persona ideas? Drop them below—I’d love to hear.
See you in the next one,
Benito
I don’t write just for myself—every post is meant to give you tools, ideas, and insights you can use right away.
🤝 Got feedback or topics you’d like me to cover? I’d love to hear from you. Your input shapes what comes next!